talabat is the region’s leading online food delivery and q-commerce platform, with operations in Kuwait, UAE, Qatar, Bahrain, Oman, Egypt, Jordan and Iraq. Aggregated, the portal has 70,000 + restaurant partners and provides job opportunities for 81,000+ delivery riders, with 4,000 employees across 80+ different nationalities.
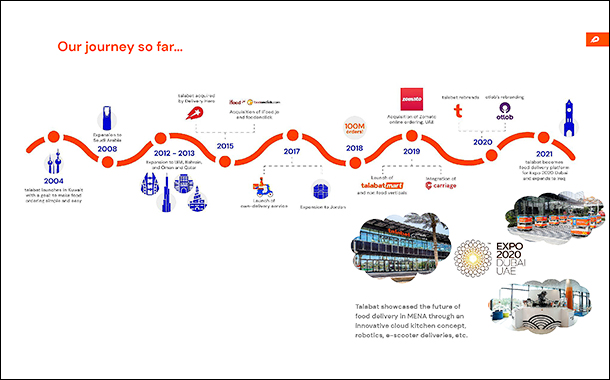
talabat was launched in 2004 in Kuwait and expanded operations into Saudi Arabia in 2008; UAE, Bahrain, Qatar, Oman in 2012-2013. It was acquired by the Delivery Hero Group in 2015.
On the technology side, talabat is one of the largest regional hubs with 300+ technology and product specialists based in Dubai. The technology team includes talent that has moved from Google, Amazon, Microsoft, LinkedIn, Careem, UBER, Grab, Yandex, amongst others.
The talabat mobile application has been downloaded 100+ million times, and the core application is updated hundreds of times a week, while it supports 100,000 actions per minute. It reached a milestone of 100 million orders in 2018.
Similar to all digital businesses today, managing operational scale, skilled teams and technology complexity are principal challenges through which all businesses progress and master.
Continuous growth in operations across multiple countries, exceptional growth during the pandemic lockdown, partnership with Dubai Expo2020 and mergers of other operations into talabat, have been growth milestones that the product development and technology teams have had to navigate inside talabat. Innovative use of Kafka from Confluent has helped talabat to move forward effectively.

Growth of teams
When talabat was formed in 2004, it was a fast-paced start-up with a focus on rapid delivery. Everybody knew all the complete architecture and how the different components worked together at that time as the team was still small” reflects Sven Herzing, Chief Technology Officer, talabat.
The first big change was when talabat was acquired in 2015 and became part of the larger delivery Hero Group. “In 2019, we started our journey as a technology and product organisation,” he adds.

From 2019 to 2021, the role and scale of operations of the technology team changed quite rapidly. The team size was 80 and transaction speed was an average of 140 orders per minute.
In 2020, talabat transformed into a self-organised and empowered teams’ model. The team size had grown to 200+ and transaction speed multiplied.
In 2021, talabat began to focus on building the right thing, in the right way, where speed is enabled by engineering culture and technology excellence. The team reached 250+ by middle of the year and transaction speed increase that technical limits of the stack started to show
When a start-up is using a monolithic database with many dependencies and when you add new services, it still uses the same data source. “The more we grow and scale up, we need to adjust the way we work as well as our architecture. What worked for us when we were 80 doesn’t work when we are 350 as inter-team dependencies become too big and may cause friction, as time required for teams to coordinate with others increases exponentially with the number of teams.” Herzing points out.
Every person you add to a team does not bring the same benefit because of dependencies. The code base depends on a single database which has all the schemas in there.
“If a team demands a change which hinges on another team we need to look at compatibility. The coordination efforts between teams then becomes an implication” says Herzing.
For talabat, the question was as the team has grown to over 350 people, how do you make them independent. How do you make a small team of seven or eight people independent of another team, by removing dependencies, and removing the bottleneck of a monolithic application with a monolithic database.
The requirement was that everybody needs all the data. How do you transport that across the board so that everybody can access it, without an ownership team.
“If you have Terabyte of data on your main database, then the data definition language change actually takes a while. It is no longer a millisecond but it is a couple of minutes,” says Herzing.

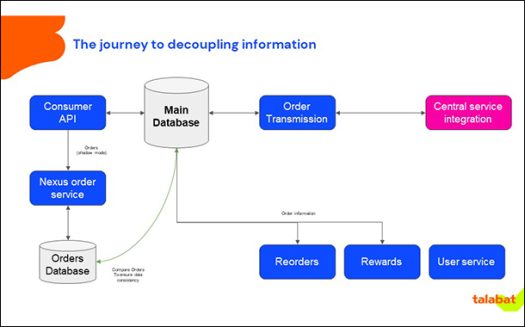
Understanding dependencies
“We have actually seen that many dependencies between the teams are reflecting on two data points, orders and vendor information. After an initial conversation we had with Confluent about how they could help us and what their solution offers to break source dependencies,” says Herzing.
At this stage, the priority for talabat was to enable teams to build services with fewer dependencies and act independently, and to drive operational speed by decoupling of functionalities between teams.
This was expected to allow the organisation to scale in order volume and team size and reduce operational cost around the monolithic application and monolithic database.
talabat’s technology and application architecture had reached a stage where, “adding more people to the team did not make us faster, but made the problem more pressing,” says Herzing. Since the code was dependent on the existence of the monolithic database, the monolithic database had become the orchestrator and limiter of team performance by coupling and dependencies between teams and services would need to be resolved.
While inside talabat, most services needed order and vendor information to function, the challenge was that, “no service should depend on another service for data availability, functionality or uptime,” says Herzing.
talabat moves ahead with Kafka
After incorporating Kafka from Confluent, a number of positive changes and initiatives have materialised. Amongst the changes initiated with Kafka are:
Make every team independent
Allow them to move independently
Break dependencies on a single source of truth
Plan to allow scale
Teams can now build their own services with fewer dependencies on other teams and act independently. All events are being streamed with full data, reducing dependencies on the individual teams to provide data or services. Data can also be cached locally.
This is boosting the operational speed of the teams through the decoupling of functionalities and all services operate independently. Further this is allowing the organisation to scale in team size and order volumes and allowing downstream services to be added without fanout requests.
Each vertical can have their own order service, creating multiple producers of events on the same stream. With this, the source of truth will be the stream and not the monolithic database, hence there is a decoupling. There is a move away from a single database with all the data leading to reduction in operational cost. Disaster recovery also becomes simplified in setup by reducing data dependencies.
On the other hand, event schemas need more upfront thinking in design to make the best out of the solution.
Kafka from Confluent
Kafka answers the needs of the modern-day company that is trying to be digital first. The challenge with building a complex IT environment is that generally you have to connect an application to a database, and that is a very tight coupling.
If you change anything on the database or the application side, you need to evolve that connection, that coupling. And if you think about companies that have several hundreds, and in some cases thousands of databases, applications located in different areas, that adds a lot of complexity.
“To simplify that architecture, Kafka decouples the sources of data to a stream of data. With Kafka, it is almost instantaneous in real time. So that is the real benefit that drives that convenience and great customer experience,” explains Fred Crehan, Area Vice President Emerging Markets, Confluent.
When talabat adopted Kafka, it looked into how to avoid the challenge and issues that every start-up faces. “Every big company wants to move fast and I actually believe the ability to iterate fast is a key to business success,” says Herzing.
While the number of orders grew significantly, a single database became a bottleneck at some point. This is a factor that limits the ability to scale horizontally and increase operational overhead.
A big database costs money and having multiple instances of it and keeping them up to scale was actually becoming expensive for talabat. “That is when you start thinking how to solve that,” says Herzing.
talabat drew a diagram of all its dependencies automatically, which looked like a big spider web in the end. However, there were some meeting points as well including orders and vendor information.
“We thought about this afterwards, and how do you provide this information to everybody in real time, so that they can consume it on their own,” reflects Herzing. talabat started publishing this data on a Kafka topic using schema registry from Confluent. “It works great but you need to be careful how to employ it,” he points out.
Technology snapshot
-
- talabat is working with the data warehouse team, beginning next year to consume the data stream into the BI solution.
- The product and technology team scaled rapidly over the last 3 years, quadrupling its size and still continuing to grow
- The talabat monolithic application and database are built with .Net core running on SQL server and hosted on AWS as a public cloud. It is supported by 35+ technology teams using 150+ services. Newer services are using .Net core or golang and PostgreSQL databases
Kafka changes ops
Using Kafka, talabat publishes all the data using a schema registry that makes sure the data is sent to a stream in the same format and does not cause any downstream problems. In other words, publish the same schema to the consumers of the data and then they can consume it as they want.
talabat now puts all the data required for a set of services into an event using a fat event to provide all data needed to process it, as compared to only sending identifiers on the stream.
With this, every downstream consumer has all the data related to the order including items, amount, vendor address, location, rider information and customer’s address, all in one event. This avoids the requirement of sending out queries after the event is generated by the various teams.
Other than order events, the Kafka data stream also has order status events. Everybody who influences the order event, and that could be multiple producers, writes to the order status event stream with the consumer correlating the data. All change events get collated and evaluated and then sent again as a stream.
talabat emits all events to the Kafka stream, which then replaces part of the monolithic database over time. Whatever can be covered by the data stream and the consumer, is removed over time from the monthly code base to lighten the workload on the monolith database. This makes it easier to work in the code base. “Smaller code bases are easy to understand, easy to build, and fast to deploy,” points out Herzing.
All talabat data is published on the Kafka stream and the teams read only the subset required and write it to the database. While the teams make changes all the time, “we try and isolate those changes to their own area. They have no dependencies but yes, dependencies still happen,” says Herzing.
Are we still too tightly coupled? What is the next evolution? How do we start to move things out? “It is a process and it is not finished,” answers Herzing. “As long as we have the monolithic application around, we will still have those dependencies,” he points out.
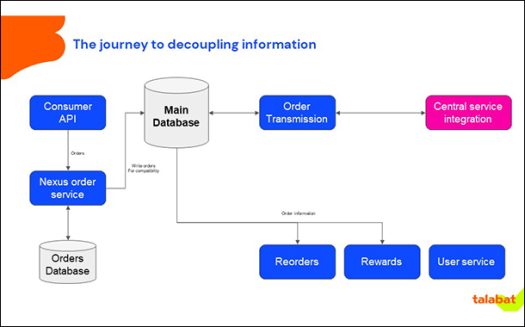
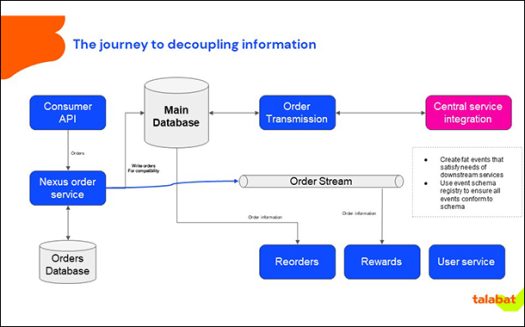
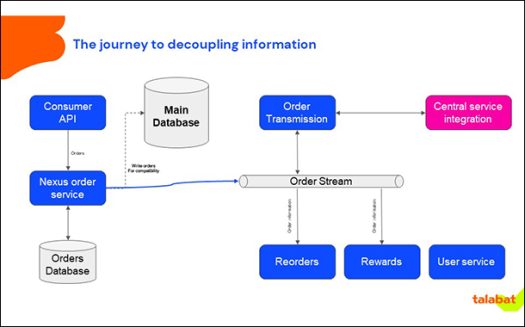
Using Kafka, Talabat publishes all the data using a schema registry that makes sure the data is sent to a stream in the same format and does not cause any downstream problems. In other words, publish the same schema to the consumers of the data and then they can consume it as they want. Talabat now puts all the data required for a set of services into an event and calls it a fat event differentiating it from a thin event.
This multi-country delivery portal has successfully managed to scale its development teams through the usage of event streaming using Kafka from Confluent.