
Developing the next generation of advanced AI will require powerful new computers capable of quintillions of operations per second. Meta has designed and built the AI Research SuperCluster, which is among the fastest running and will be the fastest AI supercomputer in the world when it is fully built out in mid-2022.
Meta researchers have already started using Research SuperCluster to train large models in natural language processing NLP and computer vision for research, with the aim of one day training models with trillions of parameters.
Research SuperCluster will help Meta’s AI researchers build new and better AI models that can learn from trillions of examples; work across hundreds of different languages; seamlessly analyse text, images, and video together; develop new augmented reality tools; and much more. Meta researchers will be able to train the largest models needed to develop advanced AI for computer vision, NLP, speech recognition, and more.
Research SuperCluster will help build new AI systems that can, for example, power real-time voice translations to large groups of people, each speaking a different language, so they can seamlessly collaborate on a research project or play an augmented game together.
Ultimately, the work done with Research SuperCluster will pave the way toward building technologies for the next major computing platform — the metaverse, where AI-driven applications and products will play an important role.
Historical baseline
Meta has been committed to long-term investment in AI since 2013, when Meta created the Facebook AI Research lab. In recent years, Meta has made significant strides in AI in a number of areas, including self-supervised learning, where algorithms can learn from vast numbers of unlabelled examples, and transformers, which allow AI models to reason more effectively by focusing on certain areas of their input.
To fully realise the benefits of self-supervised learning and transformer-based models, various domains, whether vision, speech, language, or for critical use cases like identifying harmful content, will require training increasingly large, complex, and adaptable models.
Computer vision, for example, needs to process larger, longer videos with higher data sampling rates. Speech recognition needs to work well even in challenging scenarios with lots of background noise, such as parties or concerts. NLP needs to understand more languages, dialects, and accents. And advances in other areas, including robotics, embodied AI, and multimodal AI will help people accomplish useful tasks in the real world.
High-performance computing infrastructure is a critical component in training such large models, and Meta’s AI research team has been building these high-powered systems for many years. The first generation of this infrastructure, designed in 2017, has 22,000 NVIDIA V100 Tensor Core GPUs in a single cluster that performs 35,000 training jobs a day. Up until now, this infrastructure has set the bar for Meta’s researchers in terms of its performance, reliability, and productivity.

Present day scenario
In early 2020, Meta decided the best way to accelerate progress was to design a new computing infrastructure from a clean slate to take advantage of new GPU and network fabric technology. Meta wanted this infrastructure to be able to train models with more than a trillion parameters on data sets as large as an Exabyte — which, to provide a sense of scale, is the equivalent of 36,000 years of high-quality video.
While the high-performance computing community has been tackling scale for decades, Meta also had to make sure it has all the needed security and privacy controls in place to protect any training data Meta use.
Unlike with Meta’s previous AI research infrastructure, which leveraged only open source and other publicly available data sets, Research SuperCluster also helps ensure that Meta research translates effectively into practice by including real-world examples from Meta’s production systems in model training.
By doing this, Meta can help advance research to perform downstream tasks such as identifying harmful content on Meta platforms as well as research into embodied AI and multimodal AI to help improve user experiences on Meta’s family of apps. Meta believe this is the first-time performance, reliability, security, and privacy have been tackled at such a scale.

Computing infrastructure
AI supercomputers are built by combining multiple GPUs into compute nodes, which are then connected by a high-performance network fabric to allow fast communication between those GPUs. Research SuperCluster today comprises a total of 760 NVIDIA DGX A100 systems as its compute nodes, for a total of 6,080 GPUs — with each A100 GPU being more powerful than the V100 used in Meta previous system.
Each DGX communicates via an NVIDIA Quantum 1600 Gbps InfiniBand two-level Clos fabric that has no oversubscription. Research SuperCluster’s storage tier has 175 Petabytes of Pure Storage FlashArray, 46 Petabytes of cache storage in Penguin Computing Altus systems, and 10 Petabytes of Pure Storage FlashBlade.
Early benchmarks on Research SuperCluster, compared with Meta’s legacy production and research infrastructure, have shown that it runs computer vision workflows up to 20 times faster, runs the NVIDIA Collective Communication Library more than nine times faster, and trains large-scale NLP models three times faster. That means a model with tens of billions of parameters can finish training in three weeks, compared with nine weeks before.
Designing and building something like Research SuperCluster is not a matter of performance alone but performance at the largest scale possible, with the most advanced technology available today.
When Research SuperCluster is complete, the InfiniBand network fabric will connect 16,000 GPUs as endpoints, making it one of the largest such networks deployed to date. Additionally, Meta designed a caching and storage system that can serve 16 TBps of training data, and Meta plans to scale it up to 1 Exabyte.
All this infrastructure must be extremely reliable, as Meta estimates some experiments could run for weeks and require thousands of GPUs. Lastly, the entire experience of using Research SuperCluster has to be researcher-friendly so Meta teams can easily explore a wide range of AI models.

Partnerships
A big part of achieving this was in working with a number of long-time partners, all of whom also helped design the first generation of Meta AI infrastructure in 2017. Penguin Computing, an SGH company, Meta’ architecture and managed services partner, worked with Meta operations team on hardware integration to deploy the cluster and helped set up major parts of the control plane.
Pure Storage provided robust and scalable storage solution. And NVIDIA provided its AI computing technologies featuring cutting-edge systems, GPUs, and InfiniBand fabric, and software stack components like NCCL for the cluster.
Research SuperCluster began as a completely remote project that the team took from a simple shared document to a functioning cluster in about a year and a half. The pandemic and industry-wide wafer supply constraints also brought supply chain issues that made it difficult to get everything from chips to components like optics and GPUs, and even construction materials — all of which had to be transported in accordance with new safety protocols.
To build this cluster efficiently, Meta had to design it from scratch, creating many entirely new Meta-specific conventions and rethinking previous ones along the way. Meta had to write new rules around Meta datacentre designs — including their cooling, power, rack layout, cabling, and networking including a completely new control plane, among other important considerations.
Meta had to ensure that all the teams, from construction to hardware to software and AI, were working in lockstep and in coordination with Meta partners.
Beyond the core system itself, there was also a need for a powerful storage solution, one that can serve terabytes of bandwidth from an Exabyte-scale storage system. To serve AI training’s growing bandwidth and capacity needs, Meta developed a storage service, AI Research Store AIRStore, from the ground up.
To optimise for AI models, AIRStore utilises a new data preparation phase that pre-processes the data set to be used for training. Once the preparation is performed one time, the prepared data set can be used for multiple training runs until it expires. AIRStore also optimises data transfers so that cross-region traffic on Meta’s inter-datacentre backbone is minimised.

Data privacy
To build new AI models that benefit the people using Meta services — whether that’s detecting harmful content or creating new AR experiences — Meta need to teach models using real-world data from Meta production systems.
Research SuperCluster has been designed from the ground up with privacy and security in mind, so that Meta’s researchers can safely train models using encrypted user-generated data that is not decrypted until right before training.
For example, Research SuperCluster is isolated from the larger Internet, with no direct inbound or outbound connections, and traffic can flow only from Meta’s production datacentres.
To meet Meta privacy and security requirements, the entire data path from Meta storage systems to the GPUs is end-to-end encrypted and has the necessary tools and processes to verify that these requirements are met at all times. Before data is imported to Research SuperCluster, it must go through a privacy review process to confirm it has been correctly anonymised or alternative privacy safeguards have been put in place to protect the data.
The data is then encrypted before it can be used to train AI models and both the data, and the decryption keys are deleted regularly to ensure older data is not still accessible. And since the data is only decrypted at one endpoint, in memory, it is safeguarded even in the unlikely event of a physical breach of the facility.
Road ahead
Research SuperCluster is up and running today, but its development is ongoing. Once Meta completes phase two of building out Research SuperCluster, Meta believes it will be the fastest AI supercomputer in the world, performing at nearly 5 exaflops of mixed precision compute. Through 2022, Meta will work to increase the number of GPUs from 6,080 to 16,000, which will increase AI training performance by more than 2.5x.
The InfiniBand fabric will expand to support 16,000 ports in a two-layer topology with no oversubscription. The storage system will have a target delivery bandwidth of 16 TBps and Exabyte-scale capacity to meet increased demand.
Meta expects such a step function change in compute capability to enable more accurate AI models for Meta existing services, and to enable completely new user experiences, especially in the metaverse.
Meta’s long-term investments in self-supervised learning and in building next-generation AI infrastructure with Research SuperCluster are helping us create the foundational technologies that will power the metaverse and advance the broader AI community as well.
Infrastructure snapshot
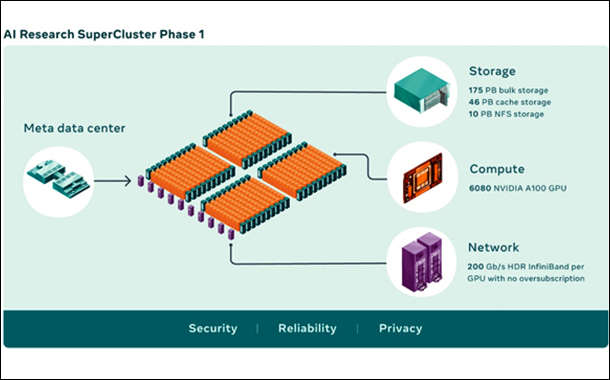
- The first generation of Research SuperCluster was designed in 2017.
- The first generation consisted of 22,000 NVIDIA V100 Tensor Core GPUs in a single cluster, with 35,000 training jobs a day.
- AI supercomputers are built by combining multiple GPUs into compute nodes.
- Compute nodes are connected by a high-performance network fabric to allow fast communication.
- Research SuperCluster today comprises a total of 760 NVIDIA DGX A100 systems as its compute nodes, for a total of 6,080 GPUs.
- Research SuperCluster’s storage tier has 175 Petabytes of Pure Storage FlashArray, 46 Petabytes of cache storage in Penguin Computing Altus systems, 10 Petabytes of Pure Storage FlashBlade.
- When Research SuperCluster is complete, the InfiniBand network fabric will connect 16,000 GPUs as endpoints, making it one of the largest such networks.
- There was a need for a powerful storage solution that can serve Terabytes of bandwidth from an Exabyte-scale storage system.
- To serve the training’s needs, Meta developed a storage service, AI Research Store AIRStore, from the ground up.
- AIRStore utilises a new data preparation phase that pre-processes the data set to be used for training.
- AIRStore optimises data transfers so that traffic on Meta’s inter-datacentre backbone is minimised.
- In 2022, Meta will work to increase the number of GPUs from 6,080 to 16,000, which will increase AI training performance by more than 2.5x.
- The InfiniBand fabric will expand to support 16,000 ports in a two-layer topology with no oversubscription.
- Research SuperCluster is isolated from the larger Internet, with no direct inbound or outbound connections.
- Inside Research SuperCluster, traffic can flow only from Meta’s production datacentres.
- The entire data path from Meta storage systems to the GPUs is end-to-end encrypted.
- Before data is imported to Research SuperCluster, it must go through a privacy review process.
- The data is encrypted before it can be used to train AI models and data and decryption keys are deleted regularly.
Performance snapshot

- Early benchmarks have shown it runs computer vision workflows up to 20 times faster.
- Research SuperCluster runs NVIDIA Collective Communication Library more than nine times faster, trains large-scale NLP models three times faster.
- A model with tens of billions of parameters can finish training in three weeks compared with nine weeks before.
- Research SuperCluster is not a matter of performance alone but performance at the largest scale possible.
- Meta designed a caching and storage system that can serve 16 TBps of training data and plans to scale it up to 1 Exabyte.
- Meta estimates experiments could run for weeks and require thousands of GPUs.
- Once Meta completes phase two it will be the fastest AI supercomputer performing at nearly 5 Exaflops of mixed precision compute.
- In 2022, Meta will increase the number of GPUs from 6,080 to 16,000, which will increase AI training performance by more than 2.5x.
- The InfiniBand fabric will expand to support 16,000 ports in a two-layer topology with no oversubscription.
- The storage system will have a delivery bandwidth of 16 TBps and Exabyte-scale capacity to meet increased demand.
Use case snapshot
- To fully realise benefits of self-supervised learning and transformer-based models will require training increasingly large, complex, and adaptable models.
- Computer vision needs to process larger, longer videos with higher data sampling rates.
- Speech recognition needs to work well even with lots of background noise.
- NLP needs to understand more languages, dialects, and accents.
- Research SuperCluster will help Meta’s AI researchers build new and better AI models that can learn from trillions of examples.
- Research SuperCluster will build real-time voice translations to large groups of people, each speaking a different language.
- Work done will pave the way toward building technologies for the next major computing platform – metaverse.
- Meta’s previous AI research infrastructure leveraged only open source and other available data sets.
- Research SuperCluster translates into practice real-world examples from Meta’s production systems into model training.
- Meta can help advance research to perform downstream tasks such as identifying harmful content on platforms.
- Meta believe this is the first-time performance, reliability, security, privacy have been tackled at such a scale.
- Meta estimates some experiments could run for weeks and require thousands of GPUs.
- Research SuperCluster has to be researcher-friendly so Meta teams can explore a wide range of AI models.
- Meta researchers have already started using Research SuperCluster to train large models in natural language processing and computer vision.
- Meta expects such a step function change in compute capability to enable completely new user experiences, especially in the metaverse.
Data snapshot
Meta’s Research SuperCluster is operating in the Exabyte range of data and above.
- 1,0001 = KB, kilobyte
- 1,0002 = MB, megabyte
- 1,0003 = GB, gigabyte
- 1,0004 = TB, terabyte
- 1,0005 = PB, petabyte
- 1,0006 = EB, exabyte
Meta has designed and built the AI Research SuperCluster, which will be the fastest AI supercomputer in the world when it is fully built out in mid-2022.

















