Meta has designed and built the AI Research SuperCluster, which is among the fastest running and will be the fastest AI supercomputer in the world when it is fully built out in mid-2022. Meta researchers are using Research SuperCluster to train large models in natural language processing, NLP and computer vision for research, with the aim of one day training models with trillions of parameters.
Research SuperCluster will help Meta’s AI researchers build new and better AI models that can learn from trillions of examples. Meta has been committed to long-term investment in AI since 2013, when Meta created the Facebook AI Research lab. High-performance computing infrastructure is a critical component in training such large models, and Meta’s AI research team has been building these high-powered systems for many years.
Meta and Pure Storage relationship
Pure Storage has been working with the Meta team since 2017 and that was the initial deployment of the FlashBlade technology. Since that time Pure Storage has been developing stronger engineering links with Meta. The Meta team chose to go with Pure Storage because the vendor was able to demonstrate years of working together successfully. This was not just on the engineering side, but also on the support and the professional services and all the other relationships that go with that when you build a system of that scale. Pure Storage already had that advantage of being the incumbent and having demonstrated those capabilities.
One of the important Meta requirements was data security and extensive use of encryption
Since 2020 Pure Storage has been working with Meta to develop the Research SuperCluster, which is a partnership primarily between Pure Storage, NVIDIA, Penguin.
The aim of Research SuperCluster is to become the world’s largest AI computer over time and to help the Meta scientists work on some of the more challenging problems they have around computer vision, language processing, and a mixture of other technologies that are being used more widely in learning systems and intelligent systems today.
The way machine learning technology works in general is that the larger the system is, the more powerful it becomes. And dividing up into smaller segments is perhaps less appealing to scientists unless they are working on a smaller training model.
Pure Storage is well known for elimination of complexity
The power of the system becomes much more strategically capable once all of the NVIGIA GPUs are used against a single model that has been trained and developed with enough calibration points. The bigger problems are the ones that the Meta team hopes to solve with the Research SuperCluster rather than specific and smaller ones.

Building and scaling the Research SuperCluster
The project to build, create, deploy the system itself is fascinating from a number of different dimensions. Meta already had a datacentre built for exactly this purpose. So Pure Storage knew that fitting into the constraints of physical space as well as power density, floor space, tile space, were already set in stone, and could not be changed.
What Pure Storage essentially ended up with was the decision to build a scalable, repeatable system that could be expanded in exactly the same way as the initial deployment. Building from an initial 250PB of capacity with six or 7,000 of NVIDIA A 100 GPUs and then repeating that in the same facility by expanding the capability.
So the requirement was designing for scale, designing for resilience, as well as making sure that everything fits within the metrics of traditional datacentre requirements in terms of power, space, cooling, density. But also leaving room to grow.
The ambition is to reach an Exabyte of model data, but also to get up towards 16,000 NVIDIA GPUs in this system as well. All of which drives specific requirements on the storage side in particular for the density and the actual bandwidth density, performance density and power density. Pure Storage had very lengthy discussions with the Meta team in terms of fulfilling those requirements.
“The Meta team had produced comprehensive specifications for all of the parameters that Pure Storage had to reach,” points out Alex McMullan, CTO International, Pure Storage.
The real design points came to, can you fit this much capacity into this much physical space, and can you consume this much power while delivering enough bandwidth to feed and sustain all of those GPUs at once. And that was a pretty big design point for Pure Storage. The vendor did have to make some enhancements to its software to help the Meta team reach those goals.
Pure Storage is well known for elimination of complexity. However, the project was unprecedented is terms of scale of deployment in a single datacentre in a very short period of time. Pure Storage wanted to make sure that this could be done quickly and easily with almost a plug and play type approach for the storage deployments themselves.
“Thinking about all these traditional deployment requirements, and also some of the non-functional requirements that sat around that as well, were part of the major success keys here in the go live,” says McMullan.
One of the important Meta requirements was data security, and the extensive use of encryption, and ensuring that the transfer of data occurred end to end on a fully encrypted state. The privacy and the security requirements for that were quite onerous, indicates McMullan. Pure Storage wanted to make sure they were comprehensively capable of meeting all of those security requirements.
“Those were the big focus for the Meta team in terms of, yes making it more secure but also making it easy to deploy on day one and continue doing so,” says McMullan. “Manageability wise, those are all pretty much standard that we have today, while making it a plug and play kind of capability for deployment.”
Another key decision point was availability. Some of the machine learning jobs and some of the training models take weeks to complete and they cannot afford to have a pause, reset, restart in that timeframe. So the physical uptime of not just the storage hardware, also the networking, the compute layers, the cache layers were all carefully considered in the Meta design. Meta was comfortable with the capabilities, resilience and uptime from Pure Storage.

Use cases at Research SuperCluster
Research SuperCluster is essentially research and a learning system. It is there to help the metadata scientists and software development teams learn about behaviours and how they can actually make their own technology better.
One of the big focuses for Meta is natural language processing, which is really aimed at things like voice assistance and being able to have a conversation with an AI machine on your phone or in your car. Those are the things Meta is trying to get better at.
In terms of the data set, the Meta ecosystem is huge, spanning all the way from Facebook application through WhatsApp and Instagram, and a whole range of others that are much more popular.
All of that data remains strongly encrypted and protected end to end in the system as part of the key design of Research SuperCluster itself. This is the way Meta learns and develops and enhances its tool sets.
Learning curve for Pure Storage
According to McMullan, the lessons Pure Storage will learn at Meta, will be those of scale and automation. It will be the single biggest deployment of Pure Storage in a single datacentre in terms of physical chip density.
Research SuperCluster gives Pure Storage a huge data set in terms of looking at how a single collection of machines behaves over time. How the various environments affect the performance, resilience, from everything in terms of chip health all the way through to power supply status. For Pure Storage this is very useful in terms of a field study of a large deployment in a single space. “That gives our engineers a lot more data points to work through,” says McMullan.
Power density capability, datacentre efficiency, are some of the most important metrics at Meta’s Research SuperCluster. And energy consumption power drain is a huge focus for Pure Storage. Power consumption and power efficiency are two operations Pure Storage looks at most carefully in its systems design. It was one of the major metrics Meta gave to Pure Storage to be able to meet. “Those kinds of metrics are becoming increasingly important,” points out McMullan.
“We do not assume that all of the other phases at Meta will come with us immediately. Pure Storage wants to just continue to earn that business,” he indicates.
For energy consumption, Pure Storage quotes the highest power levels. But power draw of storage technology in particular, will fluctuate lower than that over time. Pure Storage is working on giving customers a live view of their power consumption.
There is also a trend, according to McMullan, from Pure Storage customers to select power consumption metrics rather than performance metrics, to define a workload. And that is an interesting development that Pure Storage is looking at.
“Energy monitoring has become much more of a forefront discussion over the last couple of years. That is a great thing honestly, because it holds us as vendors to account to make sure that our systems are just as sustainable and as efficient as all the other systems we use around us today,” points out McMullan, about the innovations that lie ahead.
Compute, networking, storage architecture
In early 2020, Meta decided the best way to accelerate progress was to design a new computing infrastructure from a clean slate to take advantage of new GPU and network fabric technology. Meta wanted this infrastructure to be able to train models with more than a trillion parameters on data sets as large as an Exabyte — which, to provide a sense of scale, is the equivalent of 36,000 years of high-quality video.
The first generation of this infrastructure, designed in 2017, has 22,000 NVIDIA V100 Tensor Core GPUs in a single cluster that performs 35,000 training jobs a day. Up until now, this infrastructure has set the bar for Meta’s researchers in terms of its performance, reliability, and productivity.
AI supercomputers are built by combining multiple GPUs into compute nodes, which are then connected by a high-performance network fabric to allow fast communication between those GPUs. Research SuperCluster today comprises a total of 760 NVIDIA DGX A100 systems as its compute nodes, for a total of 6,080 GPUs — with each A100 GPU being more powerful than the V100 used in Meta previous system.
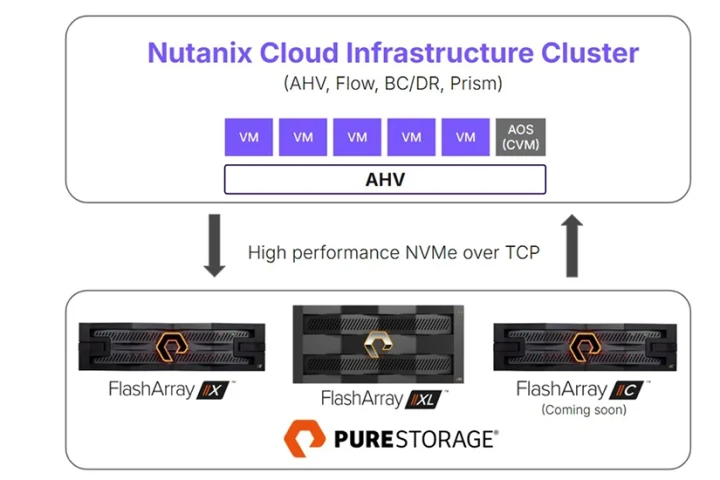
Each DGX communicates via an NVIDIA Quantum 1600 Gbps InfiniBand two-level Clos fabric. Research SuperCluster’s storage tier has 175 Petabytes of Pure Storage FlashArray, 46 Petabytes of cache storage in Penguin Computing Altus systems, and 10 Petabytes of Pure Storage FlashBlade.
When Research SuperCluster is complete, the InfiniBand network fabric will connect 16,000 GPUs as endpoints, making it one of the largest such networks deployed to date. Additionally, Meta designed a caching and storage system that can serve 16 TBps of training data, and Meta plans to scale it up to 1 Exabyte.
A big part of achieving this was in working with a number of long-time partners, all of whom also helped design the first generation of Meta AI infrastructure in 2017. Penguin Computing, an SGH company, Meta’ architecture and managed services partner, worked with Meta operations team on hardware integration to deploy the cluster and helped set up major parts of the control plane.
Pure Storage provided robust and scalable storage solution. And NVIDIA provided its AI computing technologies featuring cutting-edge systems, GPUs, and InfiniBand fabric, and software stack components like NCCL for the cluster.